
Introduction
In this post we will explore a new feature that can help to fine tune the Parallel Applier in v7.1.0. This can be achieved with the help of a new filter called ShardByRulesFilter. We will see how it works, when it could be used, and how to enable it.
Parallel Applier: How Does It Work?
Parallel Applier uses shard information to split the work between channels, each having its own connection to the database.
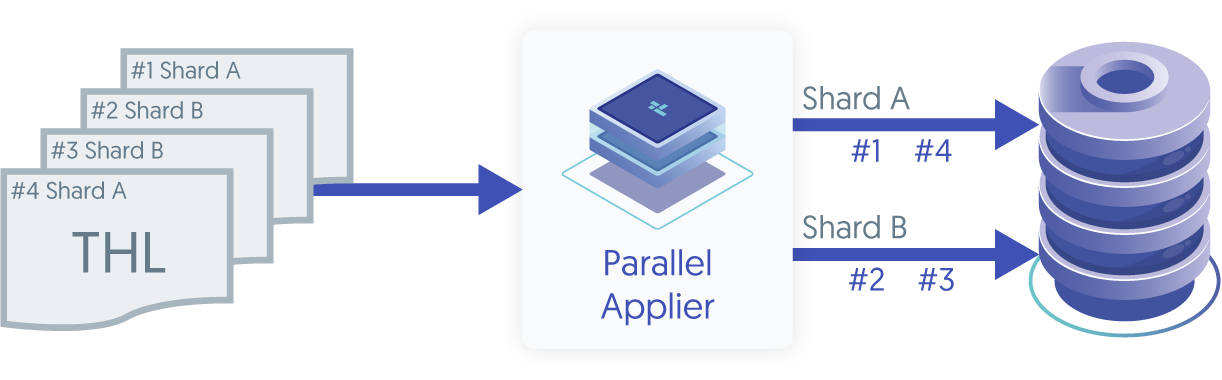
As of today, there are 2 possible ways to generate a shard for a THL event: either using the default, based on the database schema name, or using the shardbytable filter.
In the first case, the shard name is derived from the schema used within the event (or transaction). If the events are contained within a schema, this will work great, splitting events across channels. However, if an event updates tables in multiple schemas, it will be assigned to shard #UNKNOWN and this will create a serialization point, as this event cannot be run in parallel with other events.

A Small Example
Transaction 1:
mysql> BEGIN;
mysql> INSERT into example1.test VALUES (1, 'First insert');
mysql> UPDATE example1.test SET value = 'First update' where id = 1;
mysql> COMMIT;
This simple transaction will be assigned to shard example1, since every update hits only tables from the example1 schema.
Transaction 2:
mysql> BEGIN;
mysql> INSERT into example2.test VALUES (1, 'First insert in example2');
mysql> INSERT into example2.another_table VALUES (1, 'A second insert in another table from example2');
mysql> COMMIT;
Once again, this simple transaction only updates tables from one schema and will be assigned to a new shard called example2.
These 2 transactions can run in parallel since they do not interact with each other.
Transaction 3:
mysql> BEGIN;
mysql> UPDATE example1.test SET value = 'Second update' where id = 1;
mysql> UPDATE example2.test SET value = 'First update in example2' where id = 1;
mysql> COMMIT;
Note that this transaction crosses schema boundaries as it is updating both example1 and example2 schemas. The Replicator cannot run in parallel with either transaction 1 or transaction 2 and needs to force serialization between shards: one update needs to wait for previous transactions to complete before executing, and any following transactions will also need to wait for it to complete.
The second sharding method, shardbytable, will work almost the same way, but at the table level.
In the above example, transaction 1 would be assigned to shard example1_test, but the second and the third transactions would be assigned to shard #UNKNOWN, since they hit multiple tables (either in the same schema or in different schemas, that does not matter).
These two existing solutions work well, but have limitations, as we saw earlier. They do not bring a solution to the following questions:
- How can I give priority to some tables?
- How can I group tables together in one shard with some other tables going to other shards?
- How to support cross-schema updates?
Presenting the ShardByRules Filter
The reply to the above questions is a new filter, ShardByRules, introduced in our 7.1.0 release. Let’s see how it works.
This new filter uses a configuration file which contains sharding rules.
This is how an example definition file looks:
{
"default": "defaultShard",
"schemas": [
{
"schema": "example1",
"shardId": "A"
}
],
"tables": [
{
"schema": "example2",
"table": "table1",
"shardId": "B"
},
{
"schema": "example1",
"table": "table1",
"shardId": "B"
},
{
"schema": "example1",
"table": "table2",
"shardId": "A"
}
]
}
This JSON describes how sharding should happen.
The first entry in this file is the default shard option: it indicates what shard should be used for a database object (schema or table) that does not have its own rule.
Then there is a list of schema objects which maps a schema to a shard name.
And finally, a list of table objects completes the file. This will map the table database objects to a shard name.
The algorithm from there is pretty simple:
All updates in a transaction (or THL event) are scanned, and for each:
- if a table rule matches, get the shard name
- If the shard name is identical to the previous event's shard, continue
- if the shard name is different, the shard is set to #UNKNOWN (this transaction crosses shard boundaries)
- If no matching table rule is found in point 1, we check for a schema rule and apply logic from points 2 and 3
- if no rules match, we use the default shard or the #UNKNOWN shard if the previous event's shard name is not the default one.
As of today, this has the following limitations:
- Fragmented events (events that span more than 1 THL event, i.e. same SEQNO, but different FRAGNO) are marked as #UNKNOWN. This is due to the fact that a filter only knows the fragment it is processing and cannot know whether the shard would be the same in the next fragments.
- Statement based logged DML (Inserts, updates and deletes) are assigned to #UNKNOWN shard. These are not parsed fully and thus, we cannot tell if more tables than just the one that is updated should be checked during the shard assignment.
Here is an example:INSERT into schema1.table1 SELECT * from schema2.table1 LEFT OUTER JOIN schema3.table1
This would need to check the shard for all the 3 tables, but since we don’t fully parse statements, we would not be able to do so. - Some statements are marked as global when parsed and thus cannot be assigned to a shard. This includes user and grant operations.
- Finally, statements that cannot be parsed correctly are also flagged as #UNKNOWN
Proof of Concept
Let’s see how this behaves.
Default Parallel Applier
To deploy the Parallel Applier with default options, we just need to add a few lines in the tungsten.ini file of a replica node:
channels=3
svc-parallelization-type=disk
The settings above will enable the Parallel Applier after you execute `tpm update`.
Once the new configuration is live, the 3 transactions shown in the example would show the following result. Look for the three highlighted shard names in red below to see how events are parsed:
SEQ# = 8 / FRAG# = 0 (last frag)
- FILE = thl.data.0000000001
- TIME = 2023-08-10 14:28:33.0
- EPOCH# = 0
- EVENTID = mysql-bin.000008:0000000000002728;2302
- SOURCEID = demo2
- METADATA = [mysql_server_id=88;mysql_thread_id=2302;dbms_type=mysql;tz_aware=true;service=alpha;shard=example1]
- GLOBAL OPTIONS = [autocommit=1;sql_auto_is_null=0;foreign_key_checks=1;unique_checks=1;sql_mode='NO_ENGINE_SUBSTITUTION,STRICT_TRANS_TABLES';character_set_client=255;collation_connection=255;collation_server=255]
- TYPE = com.continuent.tungsten.replicator.event.ReplDBMSEvent
- OPTIONS = [foreign_key_checks = 1, unique_checks = 1, time_zone = '+00:00', ##charset = UTF-8]
- SQL(0) =
- ACTION = INSERT
- SCHEMA = example1
- TABLE = test
- ROW# = 0
- COL(1: ) (size = 1) = 1
- COL(2: ) (size = 12) = First insert
- OPTIONS = [foreign_key_checks = 1, unique_checks = 1, time_zone = '+00:00', ##charset = UTF-8]
- SQL(1) =
- ACTION = UPDATE
- SCHEMA = example1
- TABLE = test
- ROW# = 0
- COL(1: ) (size = 1) = 1
- COL(2: ) (size = 12) = First update
- KEY(1: ) (size = 1) = 1
- KEY(2: ) (size = 12) = First insert
SEQ# = 9 / FRAG# = 0 (last frag)
- FILE = thl.data.0000000001
- TIME = 2023-08-10 14:31:21.0
- EPOCH# = 0
- EVENTID = mysql-bin.000008:0000000000003228;2303
- SOURCEID = demo2
- METADATA = [mysql_server_id=88;mysql_thread_id=2303;dbms_type=mysql;tz_aware=true;service=alpha;shard=example2]
- GLOBAL OPTIONS = [autocommit=1;sql_auto_is_null=0;foreign_key_checks=1;unique_checks=1;sql_mode='NO_ENGINE_SUBSTITUTION,STRICT_TRANS_TABLES';character_set_client=255;collation_connection=255;collation_server=255]
- TYPE = com.continuent.tungsten.replicator.event.ReplDBMSEvent
- OPTIONS = [foreign_key_checks = 1, unique_checks = 1, time_zone = '+00:00', ##charset = UTF-8]
- SQL(0) =
- ACTION = INSERT
- SCHEMA = example2
- TABLE = test
- ROW# = 0
- COL(1: ) (size = 1) = 1
- COL(2: ) (size = 24) = First insert in example2
- OPTIONS = [foreign_key_checks = 1, unique_checks = 1, time_zone = '+00:00', ##charset = UTF-8]
- SQL(1) =
- ACTION = INSERT
- SCHEMA = example2
- TABLE = another_table
- ROW# = 0
- COL(1: ) (size = 1) = 1
- COL(2: ) (size = 46) = A second insert in another table from example2
SEQ# = 10 / FRAG# = 0 (last frag)
- FILE = thl.data.0000000001
- TIME = 2023-08-10 14:32:45.0
- EPOCH# = 0
- EVENTID = mysql-bin.000008:0000000000003745;2303
- SOURCEID = demo2
- METADATA = [mysql_server_id=88;mysql_thread_id=2303;dbms_type=mysql;tz_aware=true;service=alpha;shard=#UNKNOWN]
- GLOBAL OPTIONS = [autocommit=1;sql_auto_is_null=0;foreign_key_checks=1;unique_checks=1;sql_mode='NO_ENGINE_SUBSTITUTION,STRICT_TRANS_TABLES';character_set_client=255;collation_connection=255;collation_server=255]
- TYPE = com.continuent.tungsten.replicator.event.ReplDBMSEvent
- OPTIONS = [foreign_key_checks = 1, unique_checks = 1, time_zone = '+00:00', ##charset = UTF-8]
- SQL(0) =
- ACTION = UPDATE
- SCHEMA = example1
- TABLE = test
- ROW# = 0
- COL(1: ) (size = 1) = 1
- COL(2: ) (size = 13) = Second update
- KEY(1: ) (size = 1) = 1
- KEY(2: ) (size = 12) = First update
- OPTIONS = [foreign_key_checks = 1, unique_checks = 1, time_zone = '+00:00', ##charset = UTF-8]
- SQL(1) =
- ACTION = UPDATE
- SCHEMA = example2
- TABLE = test
- ROW# = 0
- COL(1: ) (size = 1) = 1
- COL(2: ) (size = 24) = First update in example2
- KEY(1: ) (size = 1) = 1
- KEY(2: ) (size = 24) = First insert in example2
As explained, the last transaction would be marked as #UNKNOWN, which creates a serialization point. While this may not be an issue if it happens sporadically, this will create a performance bottleneck if it happens too often.
Parallel Applier With ShardByTable Filter
To deploy Parallel Applier with the ShardByTable filter, we just need to add an extra line to the two we added previously in the tungsten.ini file of the replica node.
channels=3
svc-parallelization-type=disk
svc-remote_filters=shardbytable
Note that the filter is deployed as a remote filter (which applies the filter when the event is pulled from the upstream server) in order to see the difference in the replica THL.
It could be configured to use svc-applier-filters=shardbytable, where the shard would be computed when the event is applied by the replica, instead of when the replica fetches the event from the remote host.
With such a setting, the resulting THL events (based on the same example) look like:
SEQ# = 8 / FRAG# = 0 (last frag)
- FILE = thl.data.0000000001
- TIME = 2023-08-10 14:28:33.0
- EPOCH# = 0
- EVENTID = mysql-bin.000008:0000000000002728;2302
- SOURCEID = demo2
- METADATA = [mysql_server_id=88;mysql_thread_id=2302;dbms_type=mysql;tz_aware=true;service=alpha;shard=example1_test]
- GLOBAL OPTIONS = [autocommit=1;sql_auto_is_null=0;foreign_key_checks=1;unique_checks=1;sql_mode='NO_ENGINE_SUBSTITUTION,STRICT_TRANS_TABLES';character_set_client=255;collation_connection=255;collation_server=255]
- TYPE = com.continuent.tungsten.replicator.event.ReplDBMSEvent
[...]
SEQ# = 9 / FRAG# = 0 (last frag)
- FILE = thl.data.0000000001
- TIME = 2023-08-10 14:31:21.0
- EPOCH# = 0
- EVENTID = mysql-bin.000008:0000000000003228;2303
- SOURCEID = demo2
- METADATA = [mysql_server_id=88;mysql_thread_id=2303;dbms_type=mysql;tz_aware=true;service=alpha;shard=#UNKNOWN]
- GLOBAL OPTIONS = [autocommit=1;sql_auto_is_null=0;foreign_key_checks=1;unique_checks=1;sql_mode='NO_ENGINE_SUBSTITUTION,STRICT_TRANS_TABLES';character_set_client=255;collation_connection=255;collation_server=255]
- TYPE = com.continuent.tungsten.replicator.event.ReplDBMSEvent
[...]
SEQ# = 10 / FRAG# = 0 (last frag)
- FILE = thl.data.0000000001
- TIME = 2023-08-10 14:32:45.0
- EPOCH# = 0
- EVENTID = mysql-bin.000008:0000000000003745;2303
- SOURCEID = demo2
- METADATA = [mysql_server_id=88;mysql_thread_id=2303;dbms_type=mysql;tz_aware=true;service=alpha;shard=#UNKNOWN]
- GLOBAL OPTIONS = [autocommit=1;sql_auto_is_null=0;foreign_key_checks=1;unique_checks=1;sql_mode='NO_ENGINE_SUBSTITUTION,STRICT_TRANS_TABLES';character_set_client=255;collation_connection=255;collation_server=255]
- TYPE = com.continuent.tungsten.replicator.event.ReplDBMSEvent
[...]
As mentioned earlier, this ends up with more #UNKNOWN marked events, which would lead to more serialization on the replica. This filter is clearly designed for applications that would not hit multiple tables in transactions, or use only auto commit.
Parallel Applier With New ShardByRules Filter
Since this filter requires a configuration file, let’s create it first. Copy the template into the share directory (this ensures the configuration file will survive upgrades and so on):
cp /opt/continuent/tungsten/tungsten-replicator/support/filters-config/shards.json /opt/continuent/share/shards.json
Then edit this file and create your rules:
{
"default": "defaultShard",
"schemas": [
{
"schema": "example1",
"shardId": "shard1"
},
{
"schema": "example2",
"shardId": "shard2"
}
],
"tables": [
{
"schema": "example1",
"table": "test",
"shardId": "shard2"
}
]
}
And finally, enable the new filter by adding the following lines in your tungsten.ini:
channels=3
svc-parallelization-type=disk
svc-remote_filters=shardbyrules
property=replicator.filter.shardbyrules.definitionsFile=/opt/continuent/share/shards.json
Let’s now see what the resulting THL events would look like:
SEQ# = 8 / FRAG# = 0 (last frag)
- FILE = thl.data.0000000001
- TIME = 2023-08-10 14:28:33.0
- EPOCH# = 0
- EVENTID = mysql-bin.000008:0000000000002728;2302
- SOURCEID = demo2
- METADATA = [mysql_server_id=88;mysql_thread_id=2302;dbms_type=mysql;tz_aware=true;service=alpha;shard=shard2]
- GLOBAL OPTIONS = [autocommit=1;sql_auto_is_null=0;foreign_key_checks=1;unique_checks=1;sql_mode='NO_ENGINE_SUBSTITUTION,STRICT_TRANS_TABLES';character_set_client=255;collation_connection=255;collation_server=255]
- TYPE = com.continuent.tungsten.replicator.event.ReplDBMSEvent
[...]
SEQ# = 9 / FRAG# = 0 (last frag)
- FILE = thl.data.0000000001
- TIME = 2023-08-10 14:31:21.0
- EPOCH# = 0
- EVENTID = mysql-bin.000008:0000000000003228;2303
- SOURCEID = demo2
- METADATA = [mysql_server_id=88;mysql_thread_id=2303;dbms_type=mysql;tz_aware=true;service=alpha;shard=shard2]
- GLOBAL OPTIONS = [autocommit=1;sql_auto_is_null=0;foreign_key_checks=1;unique_checks=1;sql_mode='NO_ENGINE_SUBSTITUTION,STRICT_TRANS_TABLES';character_set_client=255;collation_connection=255;collation_server=255]
- TYPE = com.continuent.tungsten.replicator.event.ReplDBMSEvent
[...]
SEQ# = 10 / FRAG# = 0 (last frag)
- FILE = thl.data.0000000001
- TIME = 2023-08-10 14:32:45.0
- EPOCH# = 0
- EVENTID = mysql-bin.000008:0000000000003745;2303
- SOURCEID = demo2
- METADATA = [mysql_server_id=88;mysql_thread_id=2303;dbms_type=mysql;tz_aware=true;service=alpha;shard=shard2]
- GLOBAL OPTIONS = [autocommit=1;sql_auto_is_null=0;foreign_key_checks=1;unique_checks=1;sql_mode='NO_ENGINE_SUBSTITUTION,STRICT_TRANS_TABLES';character_set_client=255;collation_connection=255;collation_server=255]
- TYPE = com.continuent.tungsten.replicator.event.ReplDBMSEvent
[...]
With the provided configuration, we see that the 3 transactions would not create a serialization point (no #UNKNOWN shard is shown). These transactions could then run in parallel with any other transactions that would be sharded either with the default shard or with a different shard (for example, any transactions hitting other tables from example1 database).
Wrap-Up
This filter enables you with a more fine grain configuration of the sharding algorithm. Of course, it requires some knowledge of the application and the transactions that it does.
This filter will probably keep on improving in the future releases. Please let us know if you have any feedback, how you would like to see it improved, etc.

Comments
Add new comment