
Background
What is the recommended best practice for doing an online schema change in a Tungsten Cluster? In this blog, we’ll cover a specific procedure using a customer’s real-life use case - if you’re interested in more general information about online MySQL schema changes, please visit this blog: Perform Complex Online Schema Changes on MySQL / MariaDB / Percona Server Leveraging Tungsten Clustering.
Customer Use Case Example
Perform a schema change to modify the column data type from varchar(20) to varchar(50) on approx. 35 tables from 3GB to 10GB in size. Two of the tables are partitioned, and one of them is about 100GB combining all partitions for that table.
Solution Summary
There are two possible ways to do an online schema change:
- Perform the DDL via the Connector which will write the changes to the primary and then replicate those changes to all downstream secondaries. Good only for small changes or small tables.
- Perform the DDL multiple times on secondaries only, then switch the current primary to an updated secondary and then perform the DDL on the former Primary to complete the task.
- If the changes are compatible with the incoming writes, then Replication will simply continue to apply when brought back online.
- If the changes are NOT compatible with the incoming write traffic, then you would use filters to prevent problems.
Best Practices
- Run each change from the host you're actually updating
- Use a tool like screen to make sure you don't get disconnected from your terminal session in the middle of the change.
- Do all of the changes in staging first, to be sure you're comfortable with doing it in production, and have that staging environment, including schemas, mirror production.
Solution Details
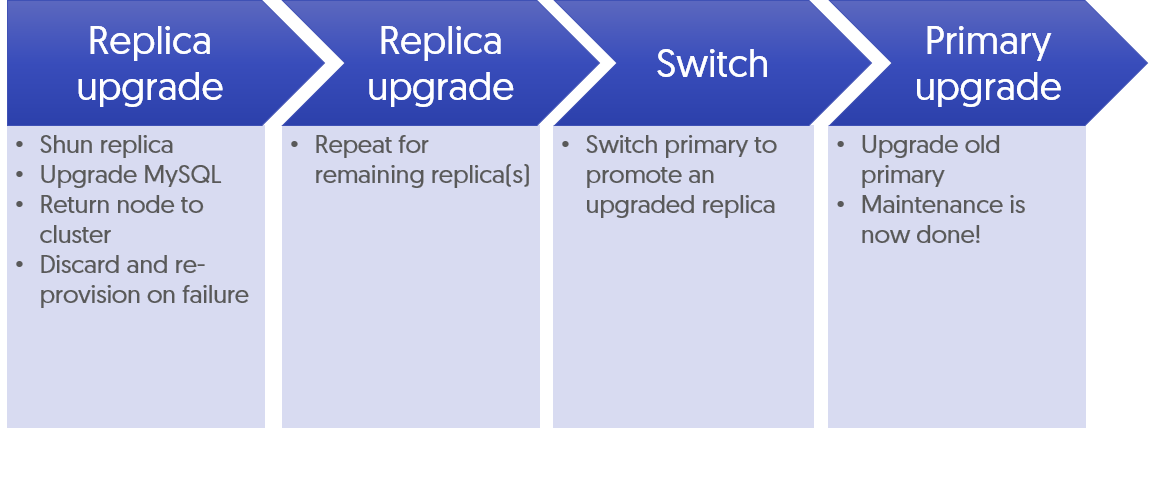
For this customer use case example, we must use option 2, the rolling schema change operation.
There is no concern about new writes failing against the updated schemas because the column sizes are larger.
The basic procedure updates all Secondary nodes one-at-a-time, then promotes one of the completed Secondary nodes to Primary, then finally updates the schema on the former Primary which is now a Secondary.
cctrl> datasource secondaryA shun
shell> trepctl -host secondaryA offline
shell> trepctl -host secondaryA status
shell> mysql -h secondaryA
mysql> set sql_log_bin=0;
mysql> Run schema change commands now;
shell> trepctl -host secondaryA online
shell> trepctl -host secondaryA status
cctrl> datasource secondaryA welcome
cctrl> datasource secondaryB shun
shell> trepctl -host secondaryB offline
shell> trepctl -host secondaryB status
shell> mysql -h secondaryB
mysql> set sql_log_bin=0;
mysql> Run schema change commands now;
shell> trepctl -host secondaryB online
shell> trepctl -host secondaryB status
cctrl> datasource secondaryB welcome
shell> cctrl
cctrl> switch
cctrl> datasource formerPrimary shun
shell> trepctl -host formerPrimary offline
shell> trepctl -host formerPrimary status
shell> mysql -h formerPrimary
mysql> set sql_log_bin=0;
mysql> Run schema change commands now;
shell> trepctl -host formerPrimary online
shell> trepctl -host formerPrimary status
cctrl> datasource formerPrimary welcome
For more information, please scroll down to the "Apply DDL Changes" section and look at the steps in the table: https://docs.continuent.com/tungsten-clustering-6.1/operations-schemachanges.html.
You may keep the nodes offline for as long as your MySQL binary log and Tungsten THL retention times are set for, no longer. The consequence of waiting too long is that the secondary would not be able to catch up via replication because un-applied THL or binary logs would be gone.
In the example below the best practice would be no longer than 5 days, which is one day less that the 6 available in the MySQL binary logs:
mysql> select @@expire_logs_days;
+--------------------+
| @@expire_logs_days |
+--------------------+
| 6 |
+--------------------+
1 row in set (0.00 sec)
shell> tpm query values repl_thl_log_retention
{
"repl_thl_log_retention": "7d"
}
https://dev.mysql.com/doc/refman/5.6/en/replication-options-binary-log.html
Wrap-Up
In a Tungsten cluster, it is possible to do a rolling schema change so that the primary is never affected.
There are two possible ways to do an online schema change:
- Perform the DDL via the Connector which will write the changes to the primary and then replicate those changes to all downstream secondaries. Good only for small changes or small tables.
- Perform the DDL multiple times on secondaries only, then switch the current primary to an updated secondary and then perform the DDL on the former Primary to complete the task.

Comments
Add new comment