
Automatic Local Failover, Automated Site Level Failover, and Automated Failback with Active/Passive MySQL Clusters
There are a number of MySQL HA solutions around. But there are surprisingly few MySQL DR solutions. And there is only one solution that does MySQL DR right!
If you read my introductory MySQL HA Done Right! blog in this series of four (4) blogs, you’ll know that I have been around MySQL availability and continuous operation solutions for some 20 years. Oh man, time flies when we are having fun, right?
I am the founder of Continuent and also godfather of Galera. Over the years we have served, and continue to serve, MySQL availability solutions for some of the biggest MySQL users. So, one would hope that I know what I’m talking about!
MySQL DR Done Right! – Part I dives into the details of MySQL Disaster Recovery with geo-distributed active/passive MySQL data service topology.
As stated in the previous blog, everything starts with [high] availability and continuous operations 24/7/365: During a failure, or a disaster, but also during the maintenance. Yes, Zero Downtime Maintenance also needs to be achieved, but more about that in an upcoming blog!
The various solutions providing MySQL high-availability and possibly also, at some level, disaster recovery capability include (in alphabetical order): AWS Aurora, Continuent Tungsten Cluster, DIY (such as ProxySQL with Orchestrator), Galera Cluster, Google Cloud SQL, MariaDB Cluster, MS Azure SQL, MySQL InnoDB Cluster and Percona XtraDB Cluster. Most of these are focusing on HA, and only a few of those also provide DR capabilities.
The list of decent MySQL disaster recovery solutions is much shorter:
- AWS Aurora (DR sort of, no Failback)
- Continuent Tungsten Cluster
- DIY (Requires custom coding, DR not automatic/automated, requires a lot manual effort to Failback)
The goal of this blog article is to showcase the simplicity of MySQL DR when Done Right.
Local Failover should be automatic and fast. Site-level Failover should be automated and fast. “Done Right” also means we can easily Failback to the original primary site when it is once again available.
Regardless of the current solution that you may have, you may want to watch the 'MySQL DR Done Right - Part I' video, or just take a look at the steps below and compare how are you doing these same steps with your own current MySQL HA/DR deployment.
If any of this peaks your interest, we currently have a Competitive Comparison program that gives you access to Tungsten Cluster software free of charge during the first six months of the agreed subscription period.
We also have a special Startup Pricing program to allow access to better Enterprise-level MySQL HA solutions at a lower Startup-level cost.
You may also be interested in other blogs/videos in this series:
- MySQL HA Done Right! (Blog/Video)
- MySQL DR Done Right! (Part II) with Active/Active MySQL Cluster (Blog/Video - due out soon!)
- MySQL Zero Downtime Maintenance Done Right! (Blog/Video - due out soon!)
MySQL HA/DR Deployment With Active/Passive Cluster
This MySQL deployment assumes that you have a local highly available MySQL data service (a 3-node Tungsten Cluster) with an identical remote MySQL data service to provide geo-scaling with local reads. And naturally, at the same time, this remote MySQL data service offers disaster recovery capabilities should the primary site go down. This setup also offers zero downtime maintenance, but more about that in a future blog article to follow.
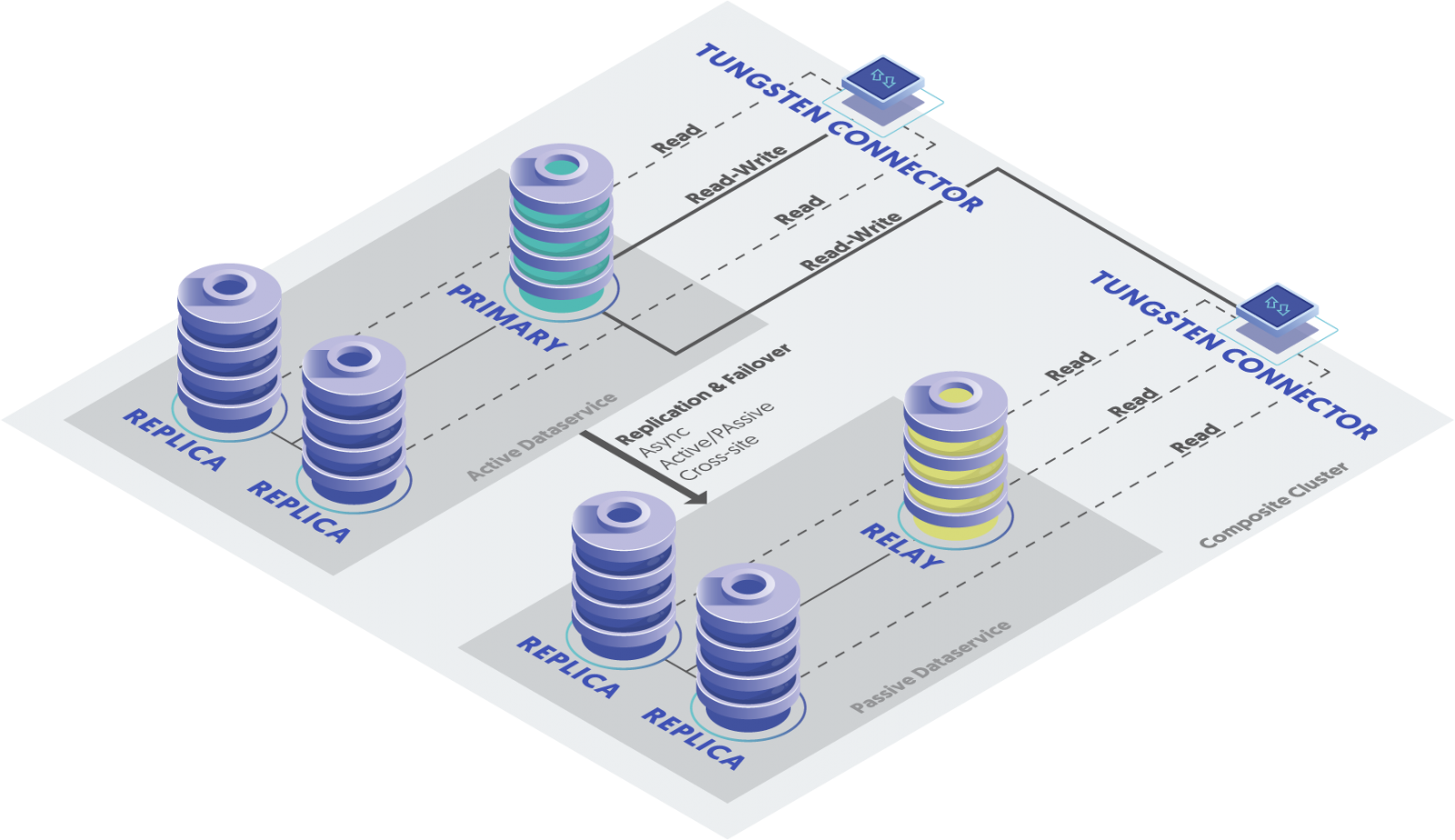
These two Tungsten data services are connected with an intelligent MySQL proxy. This intelligent MySQL proxy, Tungsten Proxy (aka Tungsten Connector), is not only aware of the local clusters but also aware of the global cluster, or a composite cluster, as we like to refer to it. So, from the application point of view, this Tungsten composite cluster appears as one complete MySQL data service, with read/write routing and global load balancing.
While the intelligent MySQL proxy acts like a smart 'traffic cop', it would not be as powerful without a control center managing the whole operation. Someone needs to feed information for the traffic cop where to route the traffic, right? This is where the Tungsten Manager comes into play. The manager service is distributed between all MySQL nodes with one acting as the coordinator between the other manager instances. Managers know the role and state (primary, replica, relay, and shunned/failed) of each member in the complete MySQL data service, both locally and globally. This allows Tungsten Managers to effectively orchestrate the operation of the data service together with the Tungsten Proxy.
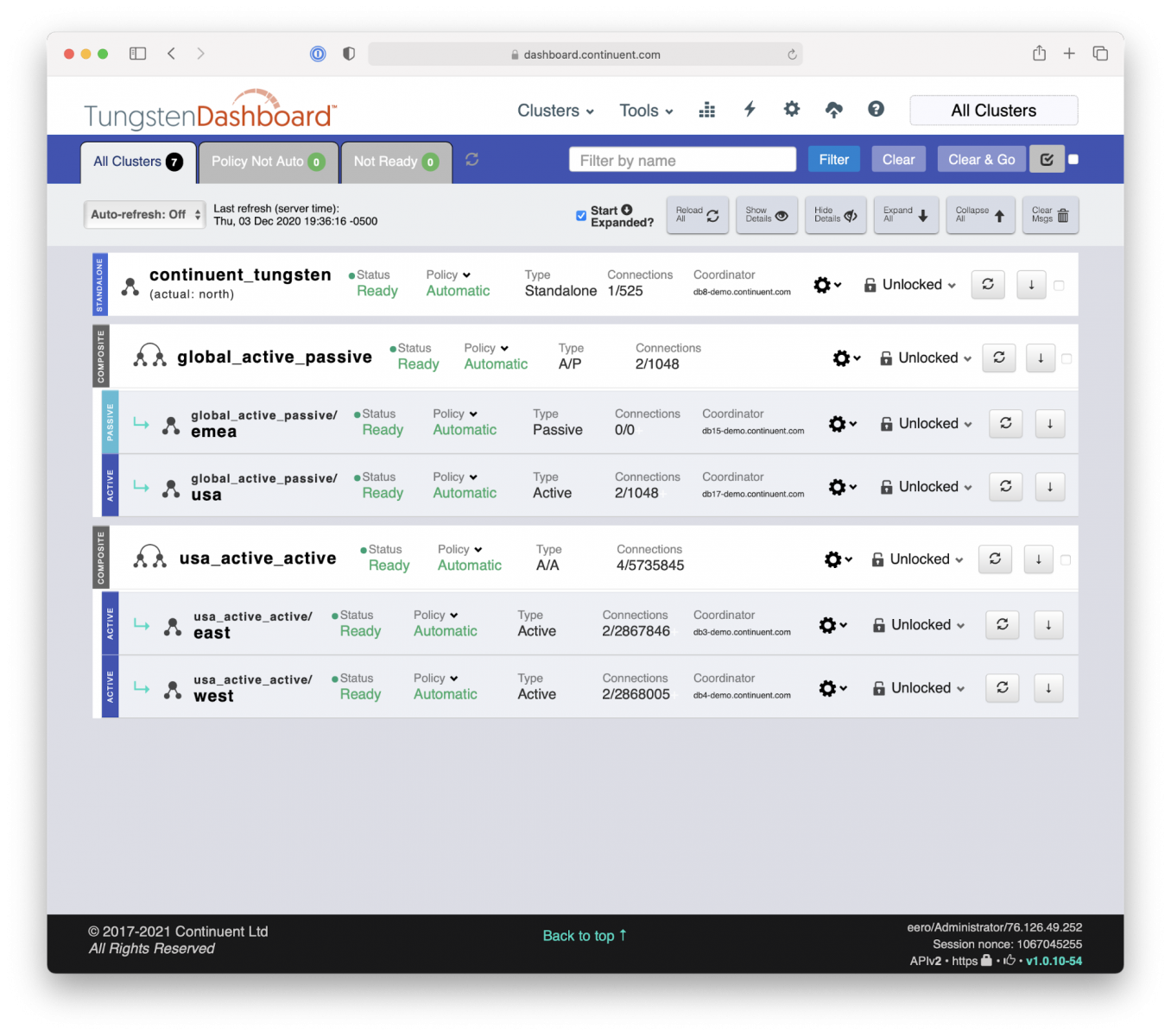
(Along with single 3-node cluster and Active/Active MySQL composite cluster)
Continuent is a USA based company with strong European roots. We also have a number of customers with deployments covering USA/EMEA. And also quite a few covering USA/EMEA/APAC on a geographically distributed composite data service, which is acting from the application point of view as one complete data service.
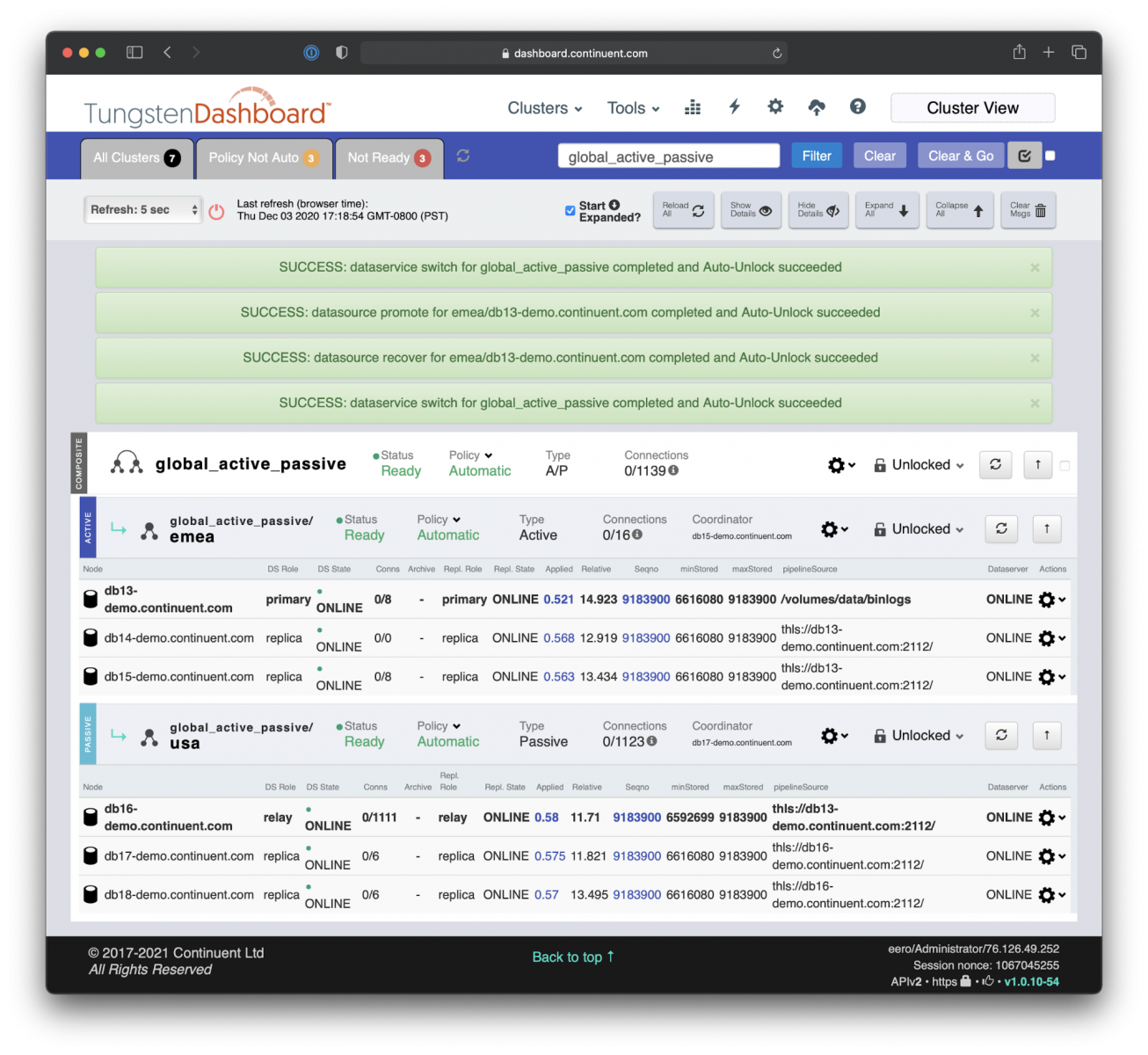
Hence, for the demo below we chose to use a ‘global_active_passive’ data service spanning across Europe (the primary site) and USA (the secondary site).
This deployment, viewed through Tungsten Dashboard, has two other data services: active/active MySQL HA/DR cluster ‘us_active_active’ and single 3-node MySQL HA cluster ‘continuent_tungsten’.
Tungsten Dashboard makes it very easy and effective to manage and monitor a number of MySQL clusters.
Automatic and Fast Local MySQL Failover for High Availability
Let’s take a look at what happens when the primary MySQL database fails. With the Tungsten Cluster solution, it is a remarkably uneventful occasion.
In the current deployment, the DB13 is the Primary MySQL database residing in Europe, in Amsterdam. It has two local replicas, DB14 and DB15, and three remote replicas (DB16, DB17, and DB18, of which DB16 is the ‘Relay Primary') on a secondary site in the USA, in Virginia.
When the unlucky DB13 fails, Tungsten Manager and Tungsten Proxy kick into action.
- Tungsten Manager gets near-immediate notification through group-communication that DB13 is out of commission.
- Manager informs Proxy to hold the traffic from the applications.
- After that Manager automatically picks the most up-to-date Replica DB15 and promotes it into the role of new Primary.
- After applying the remaining transactions to catch up with the old Primary, the new Primary database DB15 is ready to serve incoming traffic. This is typically a sub-second event.
- Manager connects the remaining Replica DB14 to the new Primary DB15 database.
- Manager notifies Proxy to open up the traffic from the applications. Voilà, we are back in action!
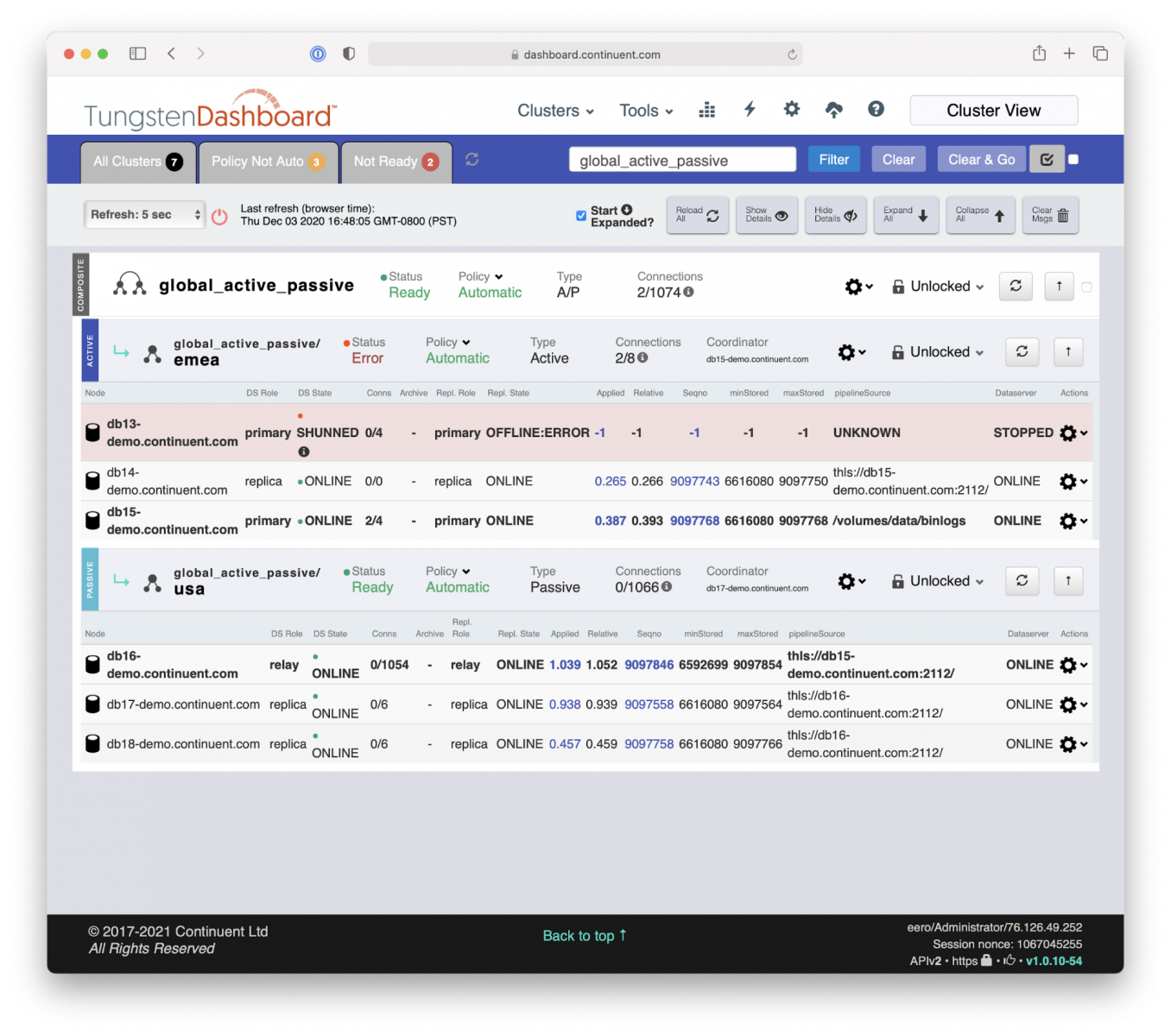
From the application’s point of view, there never was a failure, just a short, often sub-second, delay with the database servicing the application. Also, no connections were lost. Very smooth operation. In seconds. No operational impact. No human intervention needed.
If this deployment would be a simple single 3-node local cluster, no further action would be needed by the Tungsten Manager and Tungsten Proxy. Naturally, and by design, DBA intervention is needed to check out what happened to the failed database and to bring it back to the cluster. More about that later.
But since this is a cluster of clusters, a composite cluster, there is one additional step needed to be done by the Tungsten Manager.
The replication link between the new Primary DB15 database and the secondary site Relay Primary DB16 needs to be established and connected. This will also be done automatically by the Manager, and naturally very fast, once again without human intervention.
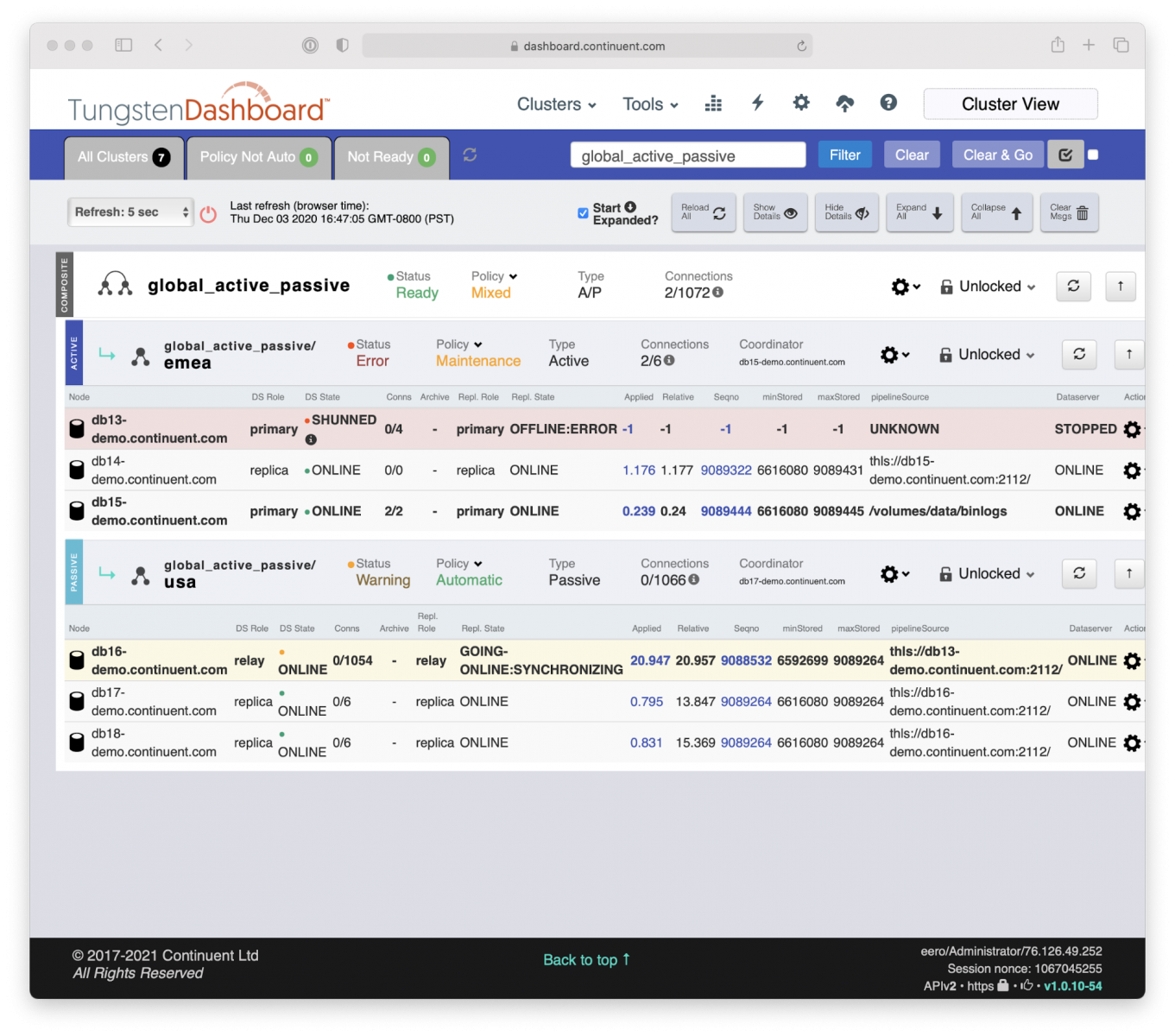
Automated and Simple Site-Level MySQL Failover for Disaster Recovery
While there was no data service interruption for the applications, we naturally do want to notify DBAs and/or Site Reliability Engineers without delay about the failure for them to take the next steps, either to recover the local service in full operation or to execute a site-level failover.
Tungsten Cluster can be integrated with various monitoring and alert systems of your choice, such as Nagios, Prometheus, and New Relic, and for example using PagerDuty for alerts.
Since we only lost one database node on the Primary site, we could try to recover the failed database and bring the cluster back into full operation. Then again, running the Primary site just with a 2-node cluster for an extended time may not be advisable, and we may want to execute the site-level failover just to be safe.
Site-level failover is never done automatically. This is a design choice to avoid possible flapping due to intermittently unreliable network connections between the sites. Also, it is very good practice for a human to take a look to understand the state of the clusters and analyze the initial failure before executing the site-level change.
After confirming that it actually is advisable to do the site failover, executing that is just one simple command: ‘Switch’ (if the original Primary site did not fail completely like it is in this case) or ‘Failover’ (if the original Primary site has completely failed).
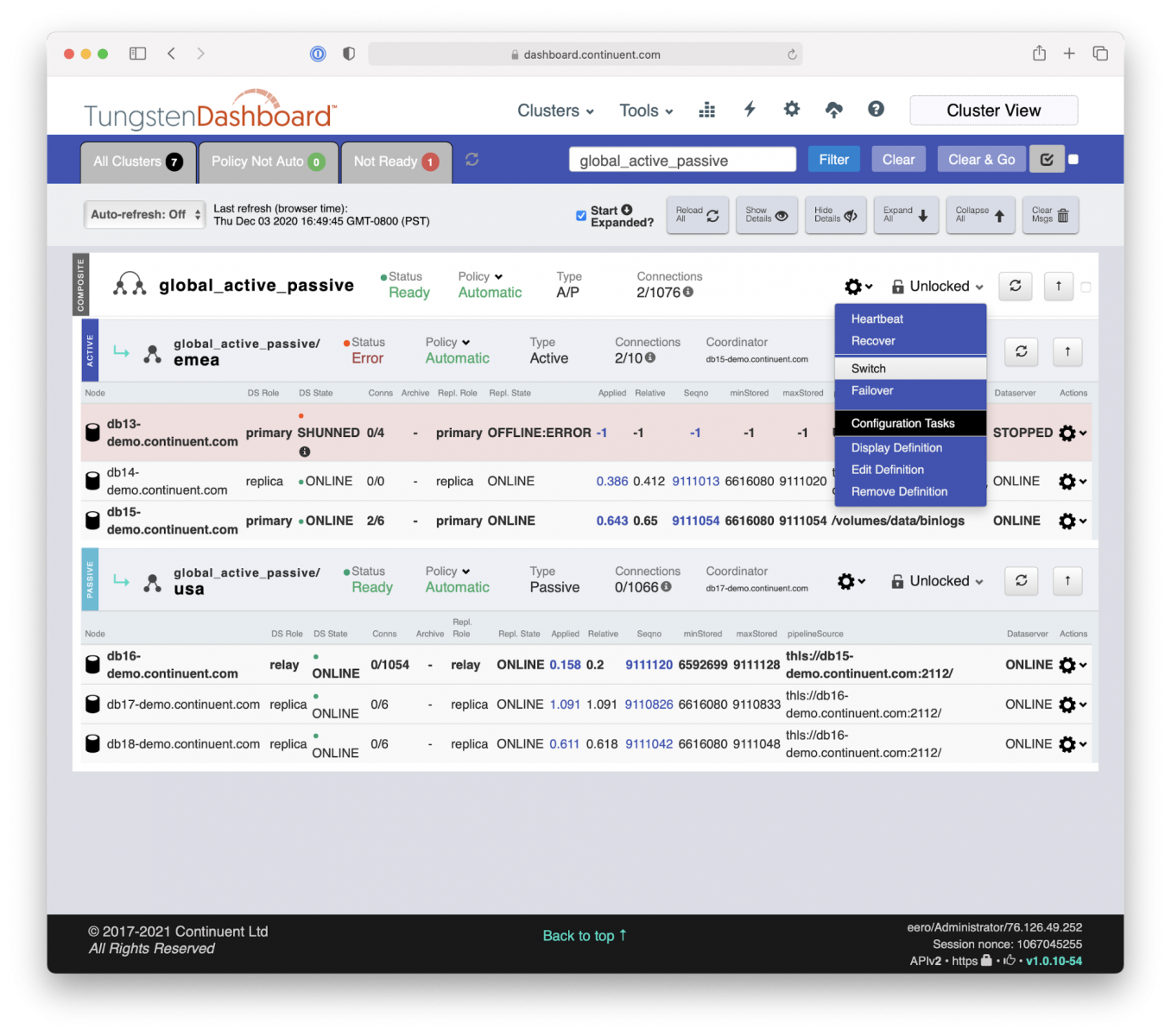
After applying the ‘Switch’ command Tungsten Manager and Tungsten Proxy kick into collaborative action; Proxy holding the traffic and Manager is coordinating all the changes needed:
- Tungsten Manager informs Proxy to hold the traffic from the applications.
- After that Manager automatically promotes the current Relay Primary DB16 as the new Primary database.
- After applying the remaining transactions to catch up with the old Primary DB15, the new Primary database DB16 is ready to serve incoming traffic. This is typically a sub-second event.
- Simultaneously Manager demotes DB15 as the Relay Primary and establishes the reverse replication link from DB16 to DB15.
- Then Manager notifies the Proxy to open up the traffic from the applications. Voilà, the Secondary site is now the Primary!
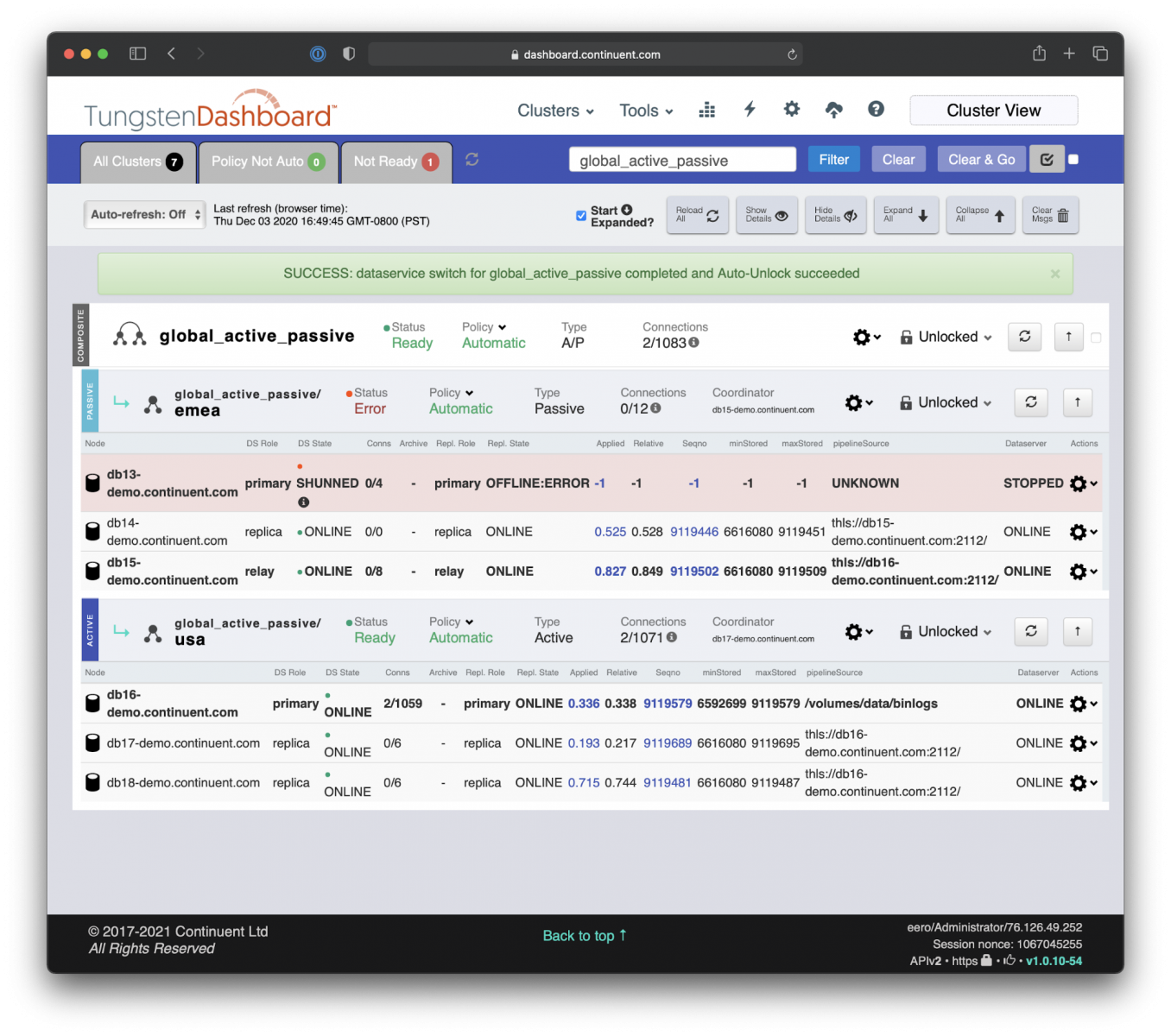
All complex changes are executed in an automated fashion after applying just a single command ‘Switch’. Could not get much easier. Or faster. And without breaking application connections.
Site-Level Recovery and Failback
After we have ensured the continuous operations at the highest possible level, now is the time to clean up, recover the failed DB13 database, promote it as a local Primary database, and then fallback to the original Primary site.
Once again, all of this is automated, but naturally only after we checked and fixed what the issue was on the DB13 in the first place.
The steps to return to the original Active/Passive state with EMEA site being the Active are as follows:
- Recover DB13 and introduce it back to the current Secondary cluster as a Replica.
- Promote DB13 as the local Primary member of the clusters.
- Execute the site-level switch to promote the original Primary site EMEA and the original Primary database DB13.
This can be achieved with three simple commands: i) ‘Recover’ applied to DB13, ‘Switch’ applied to DB13, and to finish the process iii) ‘Switch’ applied to site EMEA.
Local Database Recovery: Bring the DB13 back online with ‘Recover’ command.
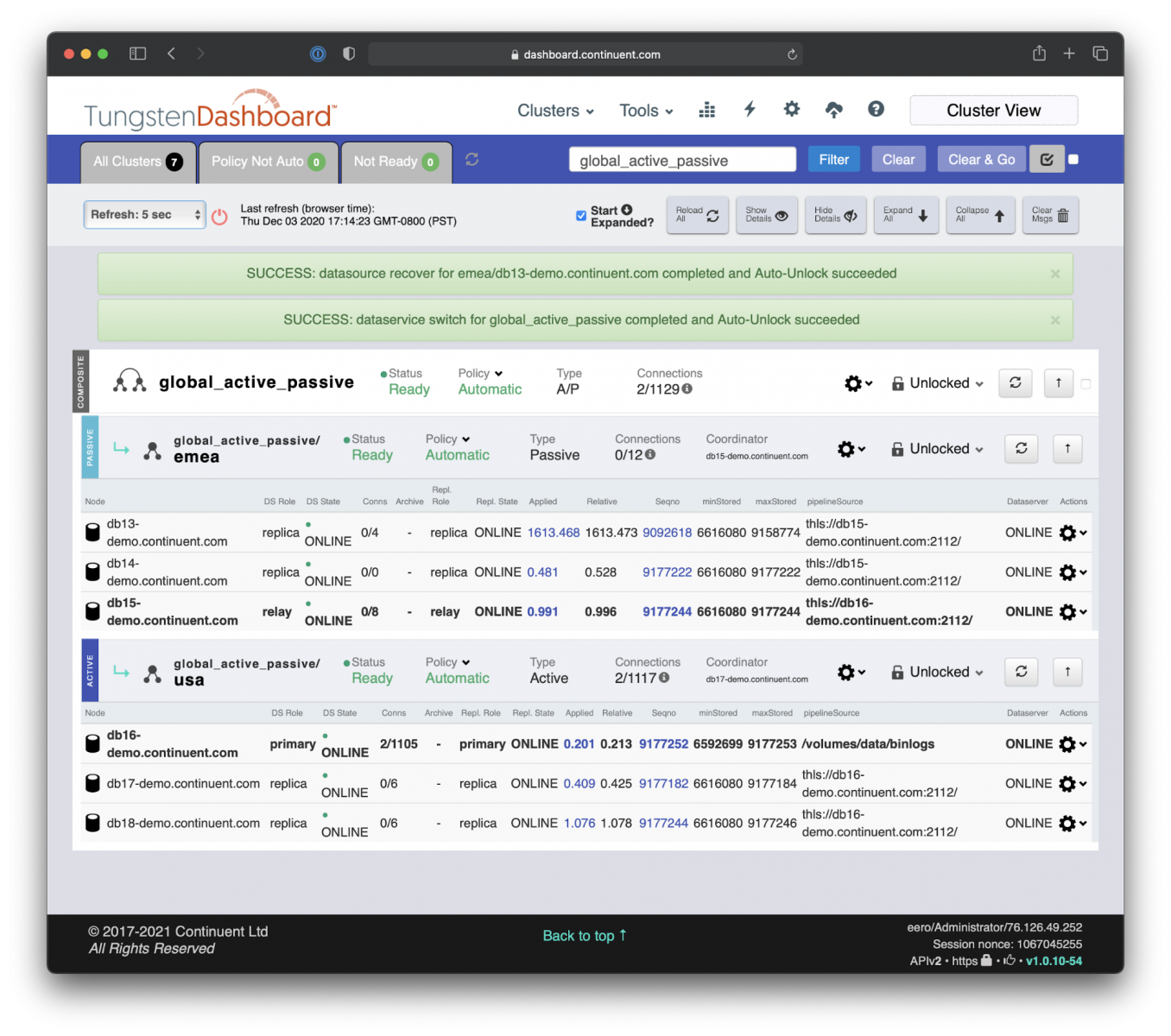
Local Primary Database Promotion: Promote the DB13 as a new Primary with a local ‘Switch’ command.
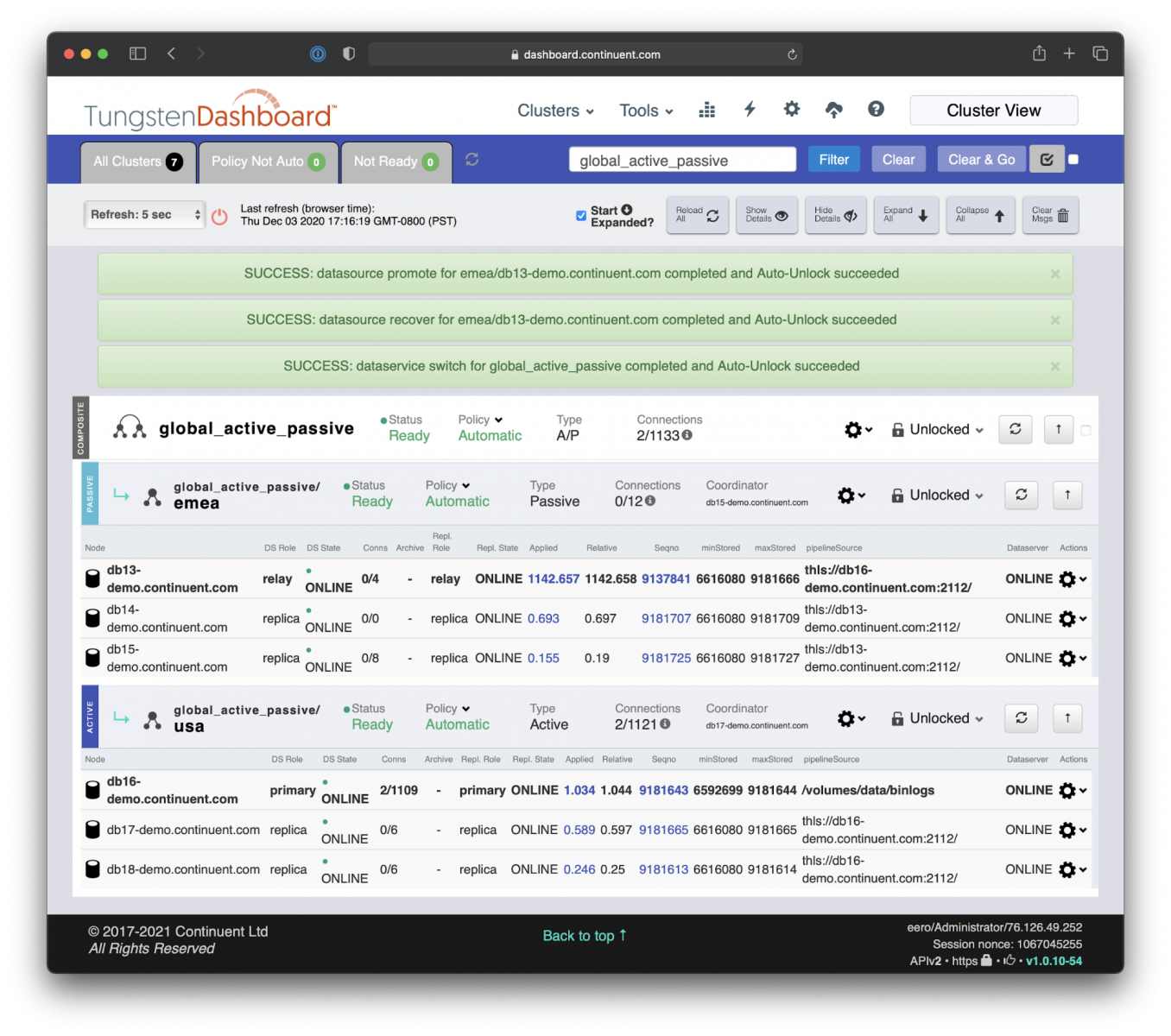
Global Switch: Promote the EMEA site as the new Primary Cluster with a global ‘Switch’ command.
This blog article showcased the simplicity of the MySQL HA/DR when Done Right for an active/passive MySQL data service topology.
It is actually quite amazing how the orchestration of the geo-distributed MySQL clusters can be made so simple, all the while the applications were kept online and servicing the clients, only with an appearance of short service delays from time-to-time while Tungsten Proxy and Tungsten Manager were doing the heavy lifting of the complex change operations with seemingly effortless ease.
I hope you enjoyed it! And if you would like to see this as a live demo, please take a look at the 'MySQL DR Done Right! - Part I' video.
Also, beside this blog you may be interested in other blogs/videos in this series:
- MySQL HA Done Right! (Blog/Video)
- MySQL DR Done Right! - Part II with Active/Active MySQL Cluster (Blog/Video - due out soon!)
- MySQL Zero Downtime Maintenance Done Right! (Blog/Video - due out soon!)
Smooth sailing,
Eero Teerikorpi
Founder and CEO, Continuent

Comments
Add new comment