
Your MySQL / MariaDB / Percona Server database cluster contains your most business-critical data. The Replica nodes must be online, healthy and in sync with the Primary in order to be viable failover candidates.
This means keeping a close watch on the health of the databases nodes from many perspectives, from ensuring sufficient disk space to testing that replication traffic is flowing.
A robust monitoring setup is essential for cluster health and viability - if your replicator goes offline and you do not know about it, then that Replica becomes effectively useless because it has stale data.
Big Brother is Watching You!
The Power of Nagios
Even while you sleep, your servers are busy, and you simply cannot keep watch all the time. Now, more than ever, with global deployments, it is literally impossible to watch everything all the time.
Enter Nagios, you best big brother ever. As a long-time player in the monitoring market, Nagios has both free and paid versions. Our examples use the free Nagios 3 version.
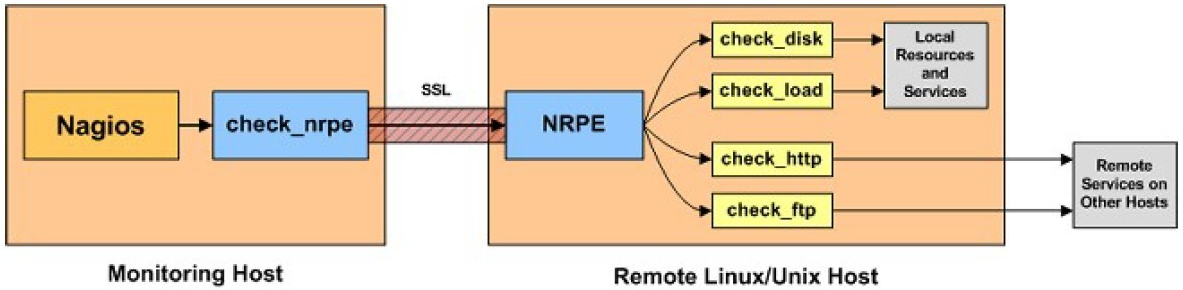
Nagios and the related NRPE daemon together enable you to monitor almost anything. Tungsten Clustering provides a number of NRPE plugins right out of the box for your monitoring convenience.
The Puzzle Pieces
How does it all fit together?
Nagios server uses services.cfg which defines a service that calls the check_nrpe binary with at least one argument - the name of the check to execute on the remote host.
Once on the remote host, the NRPE daemon processes the request from the Nagios server, comparing the check name sent by the Nagios server request with the list of defined commands in the /etc/nagios/nrpe.cfg file. If a match is found, the command is executed by the nrpe user. If different privileges are needed, then sudo must be employed.
Multi Primary Monitoring
Configuring Tungsten Cluster Monitoring with NRPE
For our example, we will have a Composite Active/Active dataservice called global with three active, writable member clusters (one per site), east, west and north.
Each site has two subservices per node, one per remote site. Each sub-service is responsible for pulling writes from the remote clusters and applying them to each node:
- Cluster east has sub-services east_from_west and east_from_north
- Cluster west has sub-services west_from_east and west_from_north
- Cluster north has sub-services north_from_east and north_from_west
That means that 3 replication services per node must be checked in addition to the datasource state. In this situation, we use a number of plugins together.
Prerequisites
Before you can use these examples
This is NOT a Nagios tutorial as such, although we present configuration examples for the Nagios framework. You will need to already have the following:
- Tungsten Clustering v6.0.0 or greater deployed as a Composite Active/Active topology
- Nagios server installed and fully functional
- NRPE installed and fully functional on each cluster node you wish to monitor
Please note that installing and configuring Nagios and NRPE in your environment is not covered in this article.
Teach the Targets
Tell NRPE on the Database Nodes What To Do
The NRPE commands are defined in the /etc/nagios/nrpe.cfg file on each monitored database node:
command[check_tungsten_online]=/usr/bin/sudo -u tungsten /opt/continuent/tungsten/cluster-home/bin/check_tungsten_online
command[check_tungsten_latency]=/usr/bin/sudo -u tungsten /opt/continuent/tungsten/cluster-home/bin/check_tungsten_latency -w 2.5 -c 4.0
command[check_tungsten_progress_east]=/usr/bin/sudo -u tungsten /opt/continuent/tungsten/cluster-home/bin/check_tungsten_progress -t 5 -s east
command[check_tungsten_progress_east_from_north]=/usr/bin/sudo -u tungsten /opt/continuent/tungsten/cluster-home/bin/check_tungsten_progress -t 5 -s east_from_north
command[check_tungsten_progress_east_from_west]=/usr/bin/sudo -u tungsten /opt/continuent/tungsten/cluster-home/bin/check_tungsten_progress -t 5 -s east_from_west
command[check_tungsten_progress_north]=/usr/bin/sudo -u tungsten /opt/continuent/tungsten/cluster-home/bin/check_tungsten_progress -t 5 -s north
command[check_tungsten_progress_north_from_east]=/usr/bin/sudo -u tungsten /opt/continuent/tungsten/cluster-home/bin/check_tungsten_progress -t 5 -s north_from_east
command[check_tungsten_progress_north_from_west]=/usr/bin/sudo -u tungsten /opt/continuent/tungsten/cluster-home/bin/check_tungsten_progress -t 5 -s north_from_west
command[check_tungsten_progress_west]=/usr/bin/sudo -u tungsten /opt/continuent/tungsten/cluster-home/bin/check_tungsten_progress -t 5 -s west
command[check_tungsten_progress_west_from_east]=/usr/bin/sudo -u tungsten /opt/continuent/tungsten/cluster-home/bin/check_tungsten_progress -t 5 -s west_from_east
command[check_tungsten_progress_west_from_north]=/usr/bin/sudo -u tungsten /opt/continuent/tungsten/cluster-home/bin/check_tungsten_progress -t 5 -s west_from_north
Note that sudo is in use to give the nrpe user access as the tungsten user to the tungsten-owned check scripts using the sudo wildcard configuration.
Additionally, there is no harm in defining commands that may not be called, which allows for simple administration - keep the Primary copy in one place and then just push updates to all nodes as needed then restart nrpe.
Big Brother Sees You
Tell the Nagios server to begin watching
Here are the service check definitions for the /opt/local/etc/nagios/objects/services.cfg file:
# Service definition
define service{
service_description check_tungsten_latency - Tungsten Clustering
servicegroups myclusters
host_name db1,db2,db3,db4,db5,db6,db7,db8,db9
check_command check_nrpe!check_tungsten_latency
contact_groups admin
use generic-service
}
# Service definition
define service{
service_description check_tungsten_online - Tungsten Clustering
servicegroups myclusters
host_name db1,db2,db3,db4,db5,db6,db7,db8,db9
check_command check_nrpe!check_tungsten_online
contact_groups admin
use generic-service
}
# Service definition
define service{
service_description check_tungsten_progress - east
host_name db1,db2,db3
check_command check_nrpe!check_tungsten_progress_east
servicegroups myclusters
contact_groups admin
use generic-service
}
# Service definition
define service{
service_description check_tungsten_progress - east_from_north
host_name db1,db2,db3
check_command check_nrpe!check_tungsten_progress_east_from_north
servicegroups myclusters
contact_groups admin
use generic-service
}
# Service definition
define service{
service_description check_tungsten_progress - east_from_west
host_name db1,db2,db3
check_command check_nrpe!check_tungsten_progress_east_from_west
servicegroups myclusters
contact_groups admin
use generic-service
}
# Service definition
define service{
service_description check_tungsten_progress - north
host_name db7,db8,db9
check_command check_nrpe!check_tungsten_progress_north
servicegroups myclusters
contact_groups admin
use generic-service
}
# Service definition
define service{
service_description check_tungsten_progress - north_from_east
host_name db7,db8,db9
check_command check_nrpe!check_tungsten_progress_north_from_east
servicegroups myclusters
contact_groups admin
use generic-service
}
# Service definition
define service{
service_description check_tungsten_progress - north_from_west
host_name db7,db8,db9
check_command check_nrpe!check_tungsten_progress_north_from_west
servicegroups myclusters
contact_groups admin
use generic-service
}
# Service definition
define service{
service_description check_tungsten_progress - west
host_name db4,db5,db6
check_command check_nrpe!check_tungsten_progress_west
servicegroups myclusters
contact_groups admin
use generic-service
}
# Service definition
define service{
service_description check_tungsten_progress - west_from_east
host_name db4,db5,db6
check_command check_nrpe!check_tungsten_progress_west_from_east
servicegroups myclusters
contact_groups admin
use generic-service
}
# Service definition
define service{
service_description check_tungsten_progress - west_from_north
host_name db4,db5,db6
check_command check_nrpe!check_tungsten_progress_west_from_north
servicegroups myclusters
contact_groups admin
use generic-service
}
NOTE: You must also add all of the hosts into the /opt/local/etc/nagios/objects/hosts.cfg file.
Security: Sudo Configuration
To enable sudo for the nrpe user, create or edit the file /etc/sudoers.d/20_nagios like so:
sudo vim /etc/sudoers.d/20_nagios
Defaults:nrpe !requiretty
Defaults:nrpe !visiblepw
nrpe ALL=(tungsten) NOPASSWD: /opt/continuent/tungsten/cluster-home/bin/check*
The above allows the nrpe OS user to execute any check scripts starting with "/opt/continuent/tungsten/cluster-home/bin/check" as the tungsten OS user.
Let's Get Practical
How to test the remote NRPE calls from the command line
The best way to ensure things are working well is to divide and conquer. My favorite approach is to use the check_nrpe binary on the command line from the Nagios server to make sure that the call(s) to the remote monitored node(s) succeed long before I configure the Nagios server daemon and start getting those evil text messages and emails.
To test a remote NRPE client command from a nagios server via the command line, use the check_nrpe command:
shell> /opt/local/libexec/nagios/check_nrpe -H db1 -c check_tungsten_latency
OK: All slaves are running normally (max_latency=0.527)
The above command calls the NRPE daemon running on host db1 and executes the NRPE command "check_tungsten_latency" as defined in the db1:/etc/nagios/nrpe.cfg file.
The Wrap-Up
Put it all together and sleep better knowing your Tungsten Cluster is under constant surveillance
Once your tests are working and your Nagios server config files have been updated, just restart the Nagios server daemon and you are on your way!
Tuning the values in the nrpe.cfg file may be required for optimal performance, as always, YMMV.
To learn about Continuent solutions in general, check out https://www.continuent.com/solutions
The Library
Please read the docs!
For more information about monitoring Tungsten clusters, please visit https://docs.continuent.com/tungsten-clustering-6.0/ecosystem-nagios.html.
Below are a list of Nagios NRPE plugin scripts provided by Tungsten Clustering. Click on each to be taken to the associated documentation page.
- check_tungsten_latency - reports warning or critical status based on the replication latency levels provided.
- check_tungsten_online - checks whether all the hosts in a given service are online and running. This command only needs to be run on one node within the service; the command returns the status for all nodes. The service name may be specified by using the -s SVCNAME option.
- check_tungsten_policy - checks whether the policy is in AUTOMATIC mode and returns a CRITICAL if not./
- check_tungsten_progress - executes a heartbeat operation and validates that the sequence number has incremented within a specific time period. The default is one (1) second, and may be changed using the -t SECS option.
- check_tungsten_services - confirms that the services and processes are running; their state is not confirmed. To check state with a similar interface, use the
check_tungsten_onlinecommand.
Tungsten Clustering is the most flexible, performant global database layer available today - use it underlying your SaaS offering as a strong base upon which to grow your worldwide business!
For more information, please visit https://www.continuent.com/solutions
Want to learn more or run a POC? Contact us.

Comments
Add new comment